OOP design principles
What is OO (Object Oriented) Programming?
One answer to this question is “The combination of data and function.” Although often cited, this is a very unsatisfying answer because it implies that o.f() is somehow different from f(o). This is absurd.
Another common answer to this question is “A way to model the real world.” This is an evasive answer at best. What does “modeling the real world” actually mean, and why is it something we would want to do? Perhaps this statement is intended to imply that OO makes software easier to understand because it has a closer relationship to the real world—but even that statement is evasive and too loosely defined. It does not tell us what OO is.
Some folks fall back on three magic words to explain the nature of OO: encapsulation, inheritance, and polymorphism. The implication is that OO is the proper admixture of these three things, or at least that an OO language must support these three things.
Let’s examine each of these concepts in turn.
Encapsulation
OO languages provide easy and effective encapsulation of data and function. As a result, a line can be drawn around a cohesive set of data and functions. Outside of that line, the data is hidden and only some of the functions are known (an Interface). We see this concept in action as the private data members and the public member functions of a class.
Inheritance
Inheritance is simply the redeclaration of a group of variables and functions within an enclosing scope. It is a mechanism where you can to derive a class from another class for a hierarchy of classes that share a set of attributes and methods.
Polymorphism (Having many forms)
Polymorphism is one of the core concepts of object-oriented programming (OOP) and describes situations in which something occurs in several different forms. In computer science, it describes the concept that you can access objects of different types through the same interface. Each type can provide its own independent implementation of this interface. It’s the polymorphism property of the OOP that give us Source code dependency inversion that we talk more about in SOLID section.
SOLID design principles at OOP or Module level
Good software systems begin with clean code which applies to the bricks of the software. Bricks are loops, conditions, definitions of functions, classes, modules etc. Two of the main principles of clean code are:
Those bricks should be readable (easily comprehensible and reasonable by humans);
And those bricks should be provable (testable).
On the one hand, if the bricks aren’t well made, the architecture of the building doesn’t matter much. On the other hand, you can make a substantial mess with well-made bricks. This is where the SOLID principles come in.
The SOLID principles tell us how to arrange our functions and data structures into classes, and how those classes should be interconnected. The use of the word “class” does not imply that these principles are applicable only to object-oriented software. A class is simply a coupled grouping of functions and data. Every software system has such groupings, whether they are called classes or not. The SOLID principles apply to those groupings.
The goal of the principles is the creation of mid-level software structures that:
Tolerate change,
Are easy to understand, and
Are the basis of components that can be used in many software systems.
S: The Single Responsibility Principle (SRP)
It is too easy for programmers to hear the name and then assume that it means that every module should do just one thing. Make no mistake, there is a principle like that. A function should do one, and only one, thing. We use that principle when we are refactoring large functions into smaller functions; we use it at the lowest levels. But it is not one of the SOLID principles—it is not the SRP.
Note
Conway’s law: The best structure for a software system is heavily influenced by the social structure of the organization that uses it.
Software systems are changed to satisfy users and stakeholders (actors); those users and stakeholders are the “reason to change” that the principle is talking about.
So we can describe SRP as:
A module should have one, and only one, reason to change.
Or:
A module should be responsible to one, and only one, actor.
Note
A module is just a cohesive set of functions and data structures.
That word “cohesive” implies the SRP. Cohesion is the force that binds together the code responsible to a single actor.
Note
You should thoroughly learn and understand the structure of the organization and actors in it for which you’re building your software as to successfully apply this principle.
Perhaps the best way to understand this principle is by looking at the symptoms of violating it.
Symptom 1: Accidental Duplication
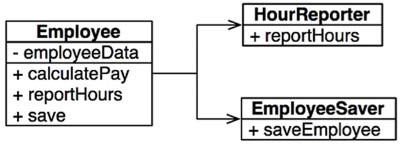
Lets say we have a an Employee class as given below:
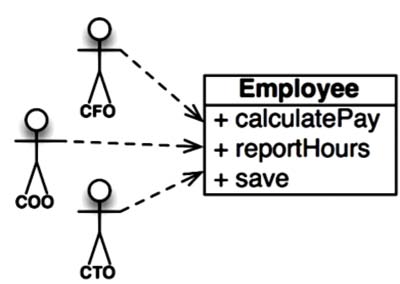
This class violates the SRP because those three methods are responsible to three very different actors.
The
calculatePay()method is specified by the accounting department, which reports to the CFO.The
reportHours()method is specified and used by the human resources department, which reports to the COO.The
save()method is specified by the database administrators (DBAs), who report to the CTO.
For example, suppose that the calculatePay() function and the reportHours() function share a common algorithm for calculating non-overtime hours a
function named regularHours().
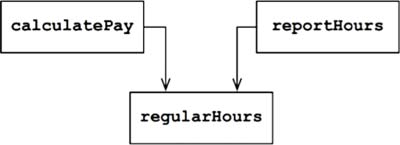
Now suppose that the CFO’s team decides that the way non-overtime hours are calculated in regularHours() needs to be tweaked. In contrast, the COO’s team in HR does not want that particular tweak because they use non-overtime hours for a different purpose. So, if one of the departments want to change how non-overtime hours are calculated then the other one will be affected, and this may cause bugs with potential economic consequences.
The main problem here is that the class have coupled each of the actors to the others thus violating SRP and causing this problematic situation.
Note
The SRP says to separate the code that different actors depend on.
Symptom 2: Merges
Suppose that the CTO’s team of DBAs decides that there should be a simple schema change to the Employee table of the database. Suppose also that the COO’s team of HR clerks decides that they need a change in the format of the hours report.
Two different developers, possibly from two different teams, check out the Employee class mentioned above and begin to make changes. Unfortunately their changes collide. The result is a merge which is a risky affair. Our tools are pretty good nowadays, but no tool can deal with every merge case. In the end, there is always risk.
These kinds of merge conflicts are also the symptoms of SRP violations. Once again, the way to avoid this problem is to separate code that supports different actors.
Solutions for the above violations
There are many different solutions to this problem. Each moves the functions into different classes using SRP.
One way to solve the problem is to separate the data from the functions. The three classes share access to EmployeeData, which is a simple data structure with no methods.
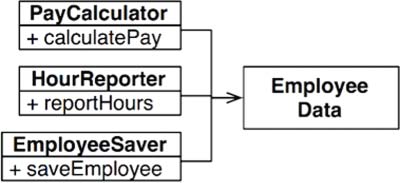
The downside of this solution is that the developers now have three classes that they have to instantiate and track. A common solution to this dilemma is to use the Facade pattern
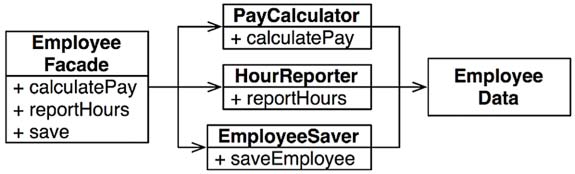
The EmployeeFacade contains very little code. It is responsible for instantiating and delegating to the classes with the functions.
The other way is done by keeping the most important method in the original Employee class and then using that class as a Facade for the lesser functions
O: The Open-Closed Principle (OCP)
The Open-Closed Principle (OCP) was coined in 1988 by Bertrand Meyer.1 It says:
A software artifact should be open for extension but closed for modification.
In other words, the behavior of a software artifact ought to be extendible, without having to modify that artifact.
Example Scenario
Lets assume that we’ve a FinancialReporter application that generates some financial reports in html form where there’re nice colors for negative and positive numbers and etc. Now assume that the client wants those financial reports now in a textual format. According to the OCP the change to the application should be nearly zero. So, the FinancialReporter application should be open to extensions but closed to modifications. Calculating reports and representing them should be in different components and add new representation should be of no cost for the report’s calculation part of the application.
Please look at the Chapter 8, Part 3 of the book Clean Architecture for detailed explanation after being familiar with all other principles of SOLID.
L: The Liskov-Substitution Principle (LSP)
In 1988, Barbara Liskov wrote the following as a way of defining subtypes.
What is wanted here is something like the following substitution property: If for each object o1 of type S there is an object o2 of type T such that for all programs P defined in terms of T , the behavior of P is unchanged when o1 is substituted for o2 then S is a subtype of T .
To understand this idea, which is known as the Liskov Substitution Principle (LSP), let’s look at some examples.
LSP example:
Imagine that we have a class named License, as shown in Figure 9.1. This class has a method named calcFee(), which is called by the Billing application. There are two “subtypes” of License: PersonalLicense and BusinessLicense. They use different algorithms to calculate the license fee.
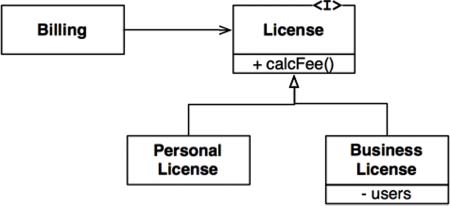
This design conforms to the LSP because the behavior of the Billing application does not depend, in any way, on which of the two subtypes it uses. Both of the subtypes are substitutable for the License type.
Non-LSP example:
The canonical example of a violation of the LSP is the famed square/rectangle problem.
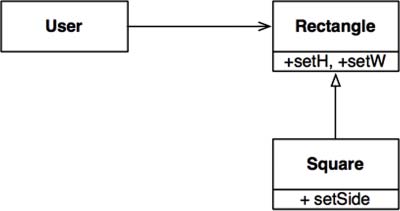
In this example, Square is not a proper subtype of Rectangle because the height and width of the Rectangle are independently mutable; in contrast, the height and width of the Square must change together. Since the User believes it is communicating with a Rectangle, it could easily get confused.
The following code shows why:
Rectangle r = ...
r.setW(5);
r.setH(2);
assert(r.area() == 10);
If the … code produced a Square, then the assertion would fail.
We can say that LSP is a way of ensuring that all of the derived classes from an Interface should strictly comply with it and should belong to the same class.
I: The Interface Segregation Principle (ISP)
The ISP’s main statement is that you should not depend on things (code) you do not use.
Lets take below example:
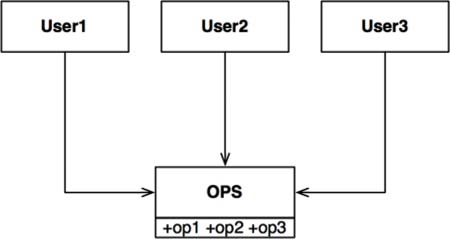
In the situation there are several users who use the operations of the OPS class. Let’s assume that User1 uses only op1, User2 uses only op2, and User3 uses only op3. This kind of structure of the code cause all of the users codes to recompile if any of the methods of OPS class changes. This is the case when the code is written in statically typed languages. To fix this we could restructure the code as below:
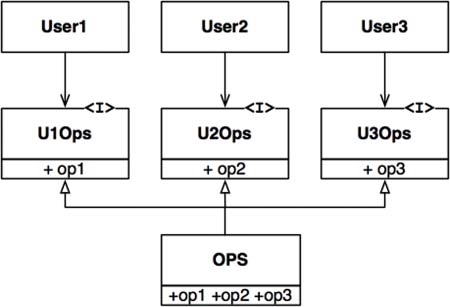
You may assume that LSP doesn’t apply if we’re using dynamically typed languages like Python. But not depending on things that you don’t use is a general design principle and it can prevent from many unnecessary and unexpected bugs whatever the language is used.
You can refer to the <Dependency hell> section for an example.
D: The Dependency Inversion Principle (DIP)
The Dependency Inversion Principle (DIP) tells us that the most flexible systems are those in which source code dependencies refer only to abstractions, not to concretions.
In a statically typed language, like Java, this means that the use, import, and include statements should refer only to source modules containing interfaces, abstract classes, or some other kind of abstract declaration. Nothing concrete should be depended on.
Its unrealistic not to depend on anything concrete. We can depend on stable implementations of libraries and others.
For these reasons, we tend to ignore the stable background of operating system and platform facilities when it comes to DIP. We tolerate those concrete dependencies because we know we can rely on them not to change.
It is the volatile concrete elements of our system that we want to avoid depending on. Those are the modules that we are actively developing, and that are undergoing frequent change.
Stable Abstractions
Every change to an abstract interface corresponds to a change to its concrete implementations. Conversely, changes to concrete implementations do not always, or even usually, require changes to the interfaces that they implement. Therefore interfaces are less volatile than implementations.
The implication, then, is that stable software architectures are those that avoid depending on volatile concretions, and that favor the use of stable abstract interfaces. This implication boils down to a set of very specific coding practices:
Don’t refer to volatile concrete classes. Refer to abstract interfaces instead. This rule applies in all languages, whether statically or dynamically typed. It also puts severe constraints on the creation of objects and generally enforces the use of Abstract Factories.
Don’t derive from volatile concrete classes. This is a corollary to the previous rule, but it bears special mention. In statically typed languages, inheritance is the strongest, and most rigid, of all the source code relationships; consequently, it should be used with great care. In dynamically typed languages, inheritance is less of a problem, but it is still a dependency—and caution is always the wisest choice.
Don’t override concrete functions. Concrete functions often require source code dependencies. When you override those functions, you do not eliminate those dependencies—indeed, you inherit them. To manage those dependencies, you should make the function abstract and create multiple implementations.
Never mention the name of anything concrete and volatile. This is really just a restatement of the principle itself.
Factories
To comply with these rules, the creation of volatile concrete objects requires special handling. This caution is warranted because, in virtually all languages, the creation of an object requires a source code dependency on the concrete definition of that object.
Lets check out below figure:
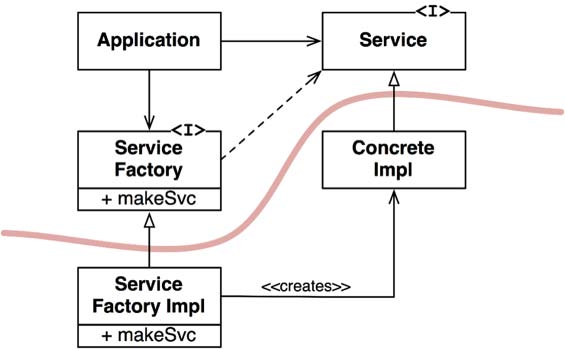
The Application uses the ConcreteImpl through the Service interface. However, the Application must somehow create instances of the ConcreteImpl. To achieve this without creating a source code dependency on the ConcreteImpl, the Application calls the makeSvc method of the ServiceFactory interface. This method is implemented by the ServiceFactoryImpl class, which derives from ServiceFactory. That implementation instantiates the ConcreteImpl and returns it as a Service.
The curved line in the figure is an architectural boundary. It separates the abstract from the concrete. All source code dependencies cross that curved line pointing in the same direction, toward the abstract side.
The curved line divides the system into two components: one abstract and the other concrete. The abstract component contains all the high-level business rules of the application. The concrete component contains all the implementation details that those business rules manipulate.
Note that the flow of control crosses the curved line in the opposite direction (from abstract side to the concrete side) of the source code dependencies. The source code dependencies are inverted against the flow of control (from concrete to abstract) — which is why we refer to this principle as Dependency Inversion.
Concrete Components
The concrete component ServiceFactoryImpl in the above figure contains a single dependency ConcreteImpl, so it violates the DIP. This is typical. DIP violations cannot be entirely removed, but they can be gathered into a small number of concrete components and kept separate from the rest of the system.
Most systems will contain at least one such concrete component—often called main because it contains the main function. In the case illustrated, the main function would instantiate the ServiceFactoryImpl and place that instance in a global variable of type ServiceFactory. The Application would then access the factory through that global variable.
What is this all about?
Software is called “soft” ware because change to an existing software is a natural thing because being soft asks for it. Client requirements change, new circumstances, new rules, new business etc. So, writing a software which is readable, easily understandable, and provable (testable) and somewhat easily changeable is the ultimate goal of every software engineer.
Above mentioned are merely principles and recommendations which are formed during a long and bloody software development practice which is intended to guide you as a software engineer to your goal. So, knowing them, understanding them deeply and being able to implement them during your career is an essential skill.
But it should be mentioned that these are not laws violation of which would be punished in any form except dealing with a messy code and can be violated if its implementation endangers someone’s life.
Note
Source:
Clean Architecture: A Craftsman’s Guide to Software Structure and Design by Robert C. Martin, Copyright © 2018 Pearson Education, Inc. Part 2, Chapter 5 and Part 3.